Learning
The main property of an ANN is its capability to learn. Learning or training is a process by means of which a neural network adapts itself to a stimulus by resulting in the production of desired response. Broadly, there are nvo kinds o{b;ning in ANNs:
1. Parameter learning: h updates the connecting weights in a neural net.
2. Strncttm learning: It focuses on the change in network structure (which includes the number of processing elemems as well as rheir connection types).
The above two types oflearn.ing can be performed simultaneously or separately. Apart from these two categories of learning, the learning in an ANN can be generally classified imo three categories as: supervised learning; unsupervised learning; reinforcement learning. Let us discuss rhese learning types in detail.
Supervised Machine Learning
Supervised Learning The learning here is performed with the help of a teacher. Let us take the example of the learning process of a small child. The child doesn't know how to readlwrite. He/she is being taught by the parenrs at home and by the reacher in school. The children are trained and molded to recognize rhe alphabets, numerals, etc. Their each and every action is supervised by a teacher. Acrually, a child works on the basis of the output that he/She has to produce
Supervised learning is the types of machine learning in which machines are trained using well "labelled" training data, and on basis of that data, machines predict the output. The labelled data means some input data is already tagged with the correct output.
In supervised learning, the training data provided to the machines work as the supervisor that teaches the machines to predict the output correctly. It applies the same concept as a student learns in the supervision of the teacher.
Supervised learning is a process of providing input data as well as correct output data to the machine learning model. The aim of a supervised learning algorithm is to find a mapping function to map the input variable(x) with the output variable(y).
In the real-world, supervised learning can be used for Risk Assessment, Image classification, Fraud Detection, spam filtering, etc.
How Supervised Learning Works?
In supervised learning, models are trained using labelled dataset, where the model learns about each type of data. Once the training process is completed, the model is tested on the basis of test data (a subset of the training set), and then it predicts the output.
The working of Supervised learning can be easily understood by the below example and diagram:
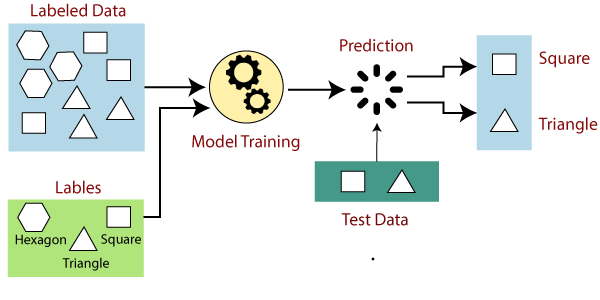
Suppose we have a dataset of different types of shapes which includes square, rectangle, triangle, and Polygon. Now the first step is that we need to train the model for each shape.
- If the given shape has four sides, and all the sides are equal, then it will be labelled as a Square.
- If the given shape has three sides, then it will be labelled as a triangle.
- If the given shape has six equal sides then it will be labelled as hexagon.
Now, after training, we test our model using the test set, and the task of the model is to identify the shape.
The machine is already trained on all types of shapes, and when it finds a new shape, it classifies the shape on the bases of a number of sides, and predicts the output.
Steps Involved in Supervised Learning:
- First Determine the type of training dataset
- Collect/Gather the labelled training data.
- Split the training dataset into training dataset, test dataset, and validation dataset.
- Determine the input features of the training dataset, which should have enough knowledge so that the model can accurately predict the output.
- Determine the suitable algorithm for the model, such as support vector machine, decision tree, etc.
- Execute the algorithm on the training dataset. Sometimes we need validation sets as the control parameters, which are the subset of training datasets.
- Evaluate the accuracy of the model by providing the test set. If the model predicts the correct output, which means our model is accurate.
Types of supervised Machine learning Algorithms:
Supervised learning can be further divided into two types of problems:
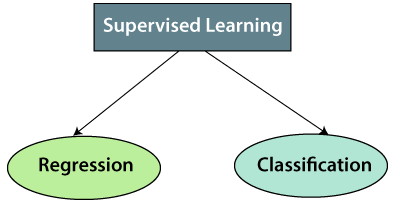
1. Regression
Regression algorithms are used if there is a relationship between the input variable and the output variable. It is used for the prediction of continuous variables, such as Weather forecasting, Market Trends, etc. Below are some popular Regression algorithms which come under supervised learning:
- Linear Regression
- Regression Trees
- Non-Linear Regression
- Bayesian Linear Regression
- Polynomial Regression
2. Classification
Classification algorithms are used when the output variable is categorical, which means there are two classes such as Yes-No, Male-Female, True-false, etc.
Spam Filtering,
- Random Forest
- Decision Trees
- Logistic Regression
- Support vector Machines
Advantages of Supervised learning:
- With the help of supervised learning, the model can predict the output on the basis of prior experiences.
- In supervised learning, we can have an exact idea about the classes of objects.
- Supervised learning model helps us to solve various real-world problems such as fraud detection, spam filtering, etc.
Disadvantages of supervised learning:
- Supervised learning models are not suitable for handling the complex tasks.
- Supervised learning cannot predict the correct output if the test data is different from the training dataset.
- Training required lots of computation times.
- In supervised learning, we need enough knowledge about the classes of object.
Unsupervised Machine Learning
Why use Unsupervised Learning?
Below are some main reasons which describe the importance of Unsupervised Learning:
- Unsupervised learning is helpful for finding useful insights from the data.
- Unsupervised learning is much similar as a human learns to think by their own experiences, which makes it closer to the real AI.
- Unsupervised learning works on unlabeled and uncategorized data which make unsupervised learning more important.
- In real-world, we do not always have input data with the corresponding output so to solve such cases, we need unsupervised learning.
Working of Unsupervised Learning
Working of unsupervised learning can be understood by the below diagram:
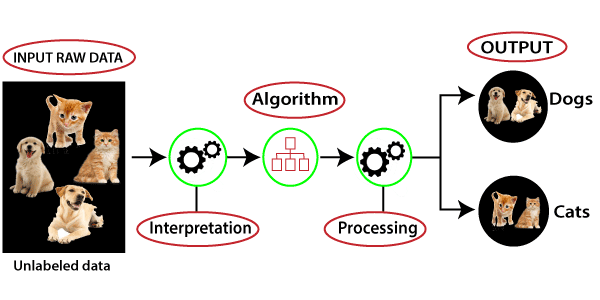
Here, we have taken an unlabeled input data, which means it is not categorized and corresponding outputs are also not given. Now, this unlabeled input data is fed to the machine learning model in order to train it. Firstly, it will interpret the raw data to find the hidden patterns from the data and then will apply suitable algorithms such as k-means clustering, Decision tree, etc.
Once it applies the suitable algorithm, the algorithm divides the data objects into groups according to the similarities and difference between the objects.
Types of Unsupervised Learning Algorithm:
The unsupervised learning algorithm can be further categorized into two types of problems:
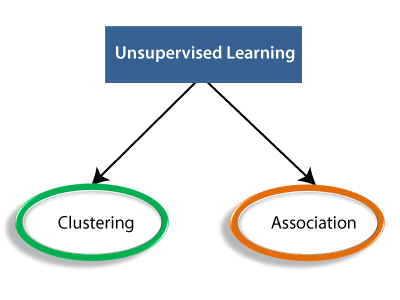
- Clustering: Clustering is a method of grouping the objects into clusters such that objects with most similarities remains into a group and has less or no similarities with the objects of another group. Cluster analysis finds the commonalities between the data objects and categorizes them as per the presence and absence of those commonalities.
- Association: An association rule is an unsupervised learning method which is used for finding the relationships between variables in the large database. It determines the set of items that occurs together in the dataset. Association rule makes marketing strategy more effective. Such as people who buy X item (suppose a bread) are also tend to purchase Y (Butter/Jam) item. A typical example of Association rule is Market Basket Analysis.
Unsupervised Learning algorithms:
Below is the list of some popular unsupervised learning algorithms:
- K-means clustering
- KNN (k-nearest neighbors)
- Hierarchal clustering
- Anomaly detection
- Neural Networks
- Principle Component Analysis
- Independent Component Analysis
- Apriori algorithm
- Singular value decomposition
Advantages of Unsupervised Learning
- Unsupervised learning is used for more complex tasks as compared to supervised learning because, in unsupervised learning, we don't have labeled input data.
- Unsupervised learning is preferable as it is easy to get unlabeled data in comparison to labeled data.
Disadvantages of Unsupervised Learning
- Unsupervised learning is intrinsically more difficult than supervised learning as it does not have corresponding output.
- The result of the unsupervised learning algorithm might be less accurate as input data is not labeled, and algorithms do not know the exact output in advance.